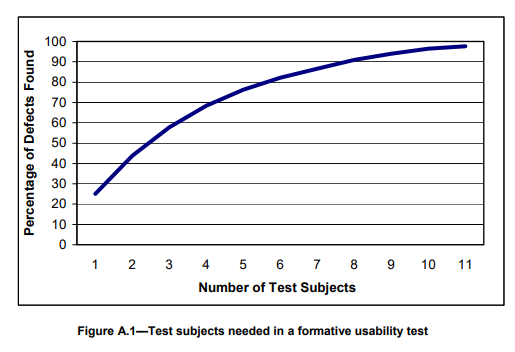
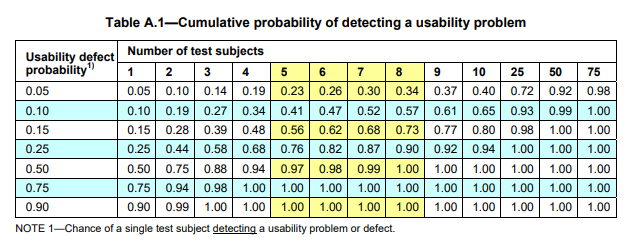
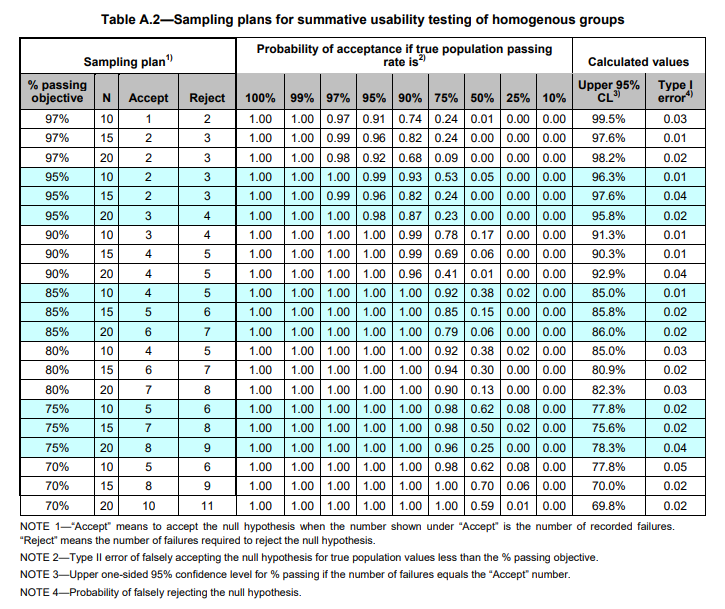
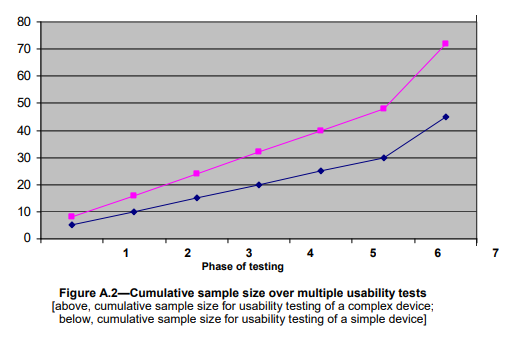
可用性测试样本量大小的统计学依据 December 28, 2023行业信息 A.1形成性可用性测试的样本量大小形成性可用性测试推荐每个同质用户组有5到8个测试对象。许多HFE专家推荐这种样本量,因为只需要少量的受试者就可以发现主要的可用性问题(Virzi, 1992)。基本原理是,在测试了五个受试者之后,收益递减法则开始起作用,因此连续的测试对象将识别出相同的主要的可用性问题,而获得更少的可用性信息。图A.1说明了在探索用户界面设计概念和早期原型的形成性可用性测试中需要多少样本量。对于单个可用性测试对象有25%的机会观察到的可用性问题,这个图表显示了5到8个对象累计发现了75%到90%的可用性问题。形成性可用性测试主要是定性的活动,而不是基于统计的活动。发现的任何和所有可用性问题都应该彻底检查根本原因,并且应该仔细考虑它们对产品成功和安全的影响。 表A.1说明了小样本是如何识别可用性问题的。它显示了在可用性测试中检测到可用性问题的累积概率,给定了单个测试将显示特定问题的潜在概率。此表适用于所有类型的人口学特征和形成性测试。例如,如果可用性问题的潜在概率为0.25,那么六个测试对象的检测累积概率为0.82。同样,许多可用性问题可以在5到8个对象的样本大小范围内被发现。该表的生成公式为R = 1 – (1 – P)n,其中R =发现可用性问题的累积概率,P =单个测试显示可用性问题的概率,n =受试者数量(测试对象/参与者) 表A.1 选择抽样计划和样本量的其他考虑因素包括:a)表面有效性:对于持怀疑态度的开发团队成员或其他评估结果的人来说,数据和由此产生的建议是否合理?b)统计效度:针对定量接受标准进行总结性可用性测试时,应考虑统计效度和信度(见A.2)。c)地域代表性:如果使用模式或临床实践存在区域差异,地域代表性很重要。地域差异通常很小,在这种情况下,不需要在一个样本中表示多个区域。d)同质与异质人群:由于受试者数量少,可用性测试通常需要在样本选择中做出实际妥协,随机抽样一般包括年龄、性别、经验水平、教育和其他变量的分层、真正随机的抽样计划很少使用。因此,通常会做出妥协:使用包含混合用户类型的混合或异构样本,而不严格遵守基于配额的分层抽样策略。e)不同的用户画像:如果用户画像显示不同的用户组(例如,说不同母语的用户或医生与护士),那么可用性测试的抽样计划应该包括这些不同的组。然后,这些样本大小的建议适用于每个不同的用户组。 A.2总结性可用性测试的样本量大小后期的总结性可用性测试需要更大的样本量,以便进行统计测试。值得注意的是,表A .2考虑了通过率周围的95%置信区间。因此,以下示例中的通过率并不表示可观察到的通过率,而是带有置信区间的通过率。虽然在人为因素领域中对样本量存在一些争议,但人们普遍认为,如果使用精确的统计测试,如精确二项测试,则可以在每个不同用户组中只使用15至20名参与者进行总结性测试。表A.2说明了使用精确二项检验对任务完成率进行假设检验的抽样计划和接受水平,该检验适用于小样本的统计检验。例子:目标:至少90%的受试者在没有指导的情况下第一次完成任务。假设检验:H0(零假设):合格率≥90%Ha(备选假设):合格率< 90%从表A .2可以看出,当样本量为15,目标任务完成率为90%时,如果≤4个被试没有成功完成任务,可用性测试是可以接受的。当15个人中有11个人成功完成任务时,95%置信上限为90.3%(或者,等价地,15个人中有4个人没有成功完成任务)。因为这个置信区间上限高于90%的目标,所以接受通过率至少为90%的零假设H0。如果15人中有5人未能完成任务,则拒绝原假设H0,得出通过率< 90%(因为如果15人中有5人未能完成任务,则95%置信上限的计算值低于90%目标值)。 想要了解更多内容? 欢迎联系诺达思咨询团队,我们将帮助您更好了解医疗器械可用性工程相关内容和服务! 获取报价及方案定制 请点击下方填写信息,我们的工作人员会尽快与您联系,根据您的具体需求给您报价,为您定制方案! 获取报价 表A.2显示,较大的样本量通常在检测问题时提供更大的统计能力。更高的统计能力意味着正确拒绝原假设的概率更高。例如,下面两种抽样计划可用于90%的通过率目标:方案1:n = 10,接受= 3,拒绝= 4方案2:n = 20,接受= 4,拒绝= 5如果真实的总体通过率为50%(不能确定,必须估计),表A.2显示n=10的计划将以0.17的概率被接受,而n=20的计划将被接受,概率是0.01。换句话说,错误地接受零假设H0的第II类误差会很低,当样本量为20时为0.01,当样本量为15时为0.17,假设真实总体通过率50%。表a .2显示了在真实总体情况下接受概率的值范围,通过率的取值范围从100%到10%。表A.2的最右一列.也显示了第一类错误的概率值。类型I误差(错误地拒绝零假设的概率)是为每个拒绝值,并表示为单个值。第二类误差的概率值在曲线上呈现,接受者工作曲线(ROC),它是真实总体通过率假设值的函数。 表A.2 如果我们感兴趣的是通过率是否高于某个目标,而不是通过率是否正好达到某个目标,那么单尾测试是合适的。即零假设是单向的。双尾统计检验及其产生的置信区间仅适用于检验通过率是否处于特定值。综上所述,更大的样本量将导致在形成性可用性测试中发现更多的可用性问题,并为总结性可用性测试中使用的统计测试提供更大的力量。一些人因专业人员提倡在30到100的范围内的样本大小,以检测形成性可用性问题的更高概率,并在总结结果中提供更高的统计置信度和更高的功率(即,更低的Type II错误概率)。一种常见的形成性测试策略是在设计阶段迭代地测试多个小样本,这样总累积样本量可能在30到80个受试者之间。图A.2显示了通过具有六个形成性测试阶段和一个总结性测试最后阶段的迭代开发周期所获得的累积样本量。对于复杂装置,每次形成性测试有8个样本,最终总结性测试有25个样本。对于简单的装置,每次形成性测试有5个样本,最终总结性测试有15个样本。好消息是,在不牺牲统计可靠性的情况下,有效的可用性测试设计可以在适度的样本量下达到对最终良好产品设计决策的信心。 “乐观”零假设背后有一个哲学,如下所示。零假设是乐观的。因为它假设形成性可用性测试的早期迭代回合已经产生了可接受的可用性水平,并且总结性可用性测试是验证乐观假设的最终检查。这一理念用于生产操作中的质量控制抽样,因为它假设迭代设计和高度可靠的制造过程将生产高质量的产品,除非来自相对较小的质量控制样本的数据表明相反。这种哲学所期望的结果是接受更有利的零假设:H0(零假设):通过率≥90%Ha(备选假设):通过率< 90%在一些消费品可用性的国际标准中支持的另一种哲学则更为保守和悲观。这一理念假设没有预先的证据表明产品的设计是为了可接受的可用性,并且验证测试采取了与零假设相反的方向:H0(零假设):合格率≤90%Ha(备选假设):通过率> 90%这种悲观的情况需要更大的样本量(例如,需要50到70的样本量来拒绝零假设H0,并接受理想的备用假设Ha)。如果可用性测试的样本量较大,这种方法更保守,也更可取。悲观的假设是,一切都不会好起来,直到数据证明并非如此(与乐观的假设相反,除非数据证明并非如此)。悲观假设的较大样本量是有利的,因为它们产生较低的I型和II型错误率,但这些样本量可能不适用于许多可用性测试情况。一些统计学家推荐悲观假设的一种变体,以减少所需的失败次数,拒绝表A.2中的原假设。这种方法有效地移动了ROC,从而降低了II类错误率(错误地接受H0),但代价是增加了I类错误率(错误地拒绝H0)。在验收标准是重要参数的验证或总结性可用性测试中,可以使用其他统计方法。除了精确的生物统计检验,还可以使用其他统计检验,包括超几何统计检验、威尔逊方法、沃德法和贝肖恩统计。总之,对于任何针对验证接受标准的统计测试,样本大小必须在统计上得到证明。 医疗器械人因工程测试